

Before the NCAA tournament begins, many different media outlets like to post their favorite Giant Killers. These are lower-seeded teams that have a good chance of pulling off an upset in the first round. However, often times these teams are one-and-done deals, flaming out in the second round after their game of glory in the first round. There is a big difference between Giant Killers and teams that can become a Cinderella and advance into the second weekend of the tournament.
Recent evidence suggests that non-conference strength of schedule could be a solid predictor of tournament success. The following model does not include strength of schedule, but it does include a whole lot of other things. The model is built with team-level KenPom advanced statistics from 2004-2015. Because success in the NCAA tournament weighs heavily on how well each team matches up with its opponent, this is one way of trying to quantify that success based on match-ups at the team level. That means no strength of schedule, no seeding information, no lottery player bias, etc.
Finding Diamonds in the Rough
Starting with 26 advanced statistics for both favorites and underdogs, the model utilizes a logistic step-wise regression, estimating the win probability for each team in Rounds 1 and 2. When trying to predict first round success with these statistics, a few statistical indicators stood out. First, both an underdog’s and a favorite’s Adjusted Offensive and Defensive Efficiencies are great predictors of a team’s tournament success. Other important factors that play into determining a first round upset seem to hinge on turnovers and three-point shooting. According to the model, the most important traits that an underdog can have are being able to turn over its opponents and shoot a high rate of threes. An underdog is much more likely to pull an upset if they are adept at forcing teams to throw the ball away on a larger share of their possessions and make favorites pay for those turnovers by hitting threes. The most important traits that favorites must posses if they wish not to beaten in Round 1 is a suffocating defense and the ability to make free throws. This makes some intuitive sense, as a high scoring underdog may be able to get hot and run-and-gun its way to an upset. A good defense would likely be a solid detractor of that possibility. Free throw shooting becomes important if an overmatched, underdog defense becomes reliant on fouling in order to slow down their more-talented opponents.
After the first round, the model moves on to selecting important factors for upsets in Round 2. When teams get to the second round, many of the same factors that predict Round 1 success also seem to carry over to Round 2, such as the favored team’s stifling defense. However, as teams get out of Round 1 and get deeper into the tournament, it seems that overall athleticism comes to mean a bit more. For Rounds 2-4, the most important indicator for an underdog is not a traditional stat, but rather the percentage of its shots that it has blocked by the defense. This pattern may define some amount of athleticism (or lack thereof) for the underdog, as a smaller, less athletic team may be prone to having its shots blocked by longer, quicker defenses. For the favorite, it’s more of the same sentiment. In Round 2 and on, the rates at which favored defenses get steals and defend the three-point line are often indicative of success. Both of these stats could reflect athleticism, as longer, quicker teams can get their hands into passing lanes and up to defend the outside jump shot.
Giant Killers and Cinderellas
Below are the results of the model, with each team’s percentage chance of winning in Round 1, Round 2, and their chances of making the Sweet 16.
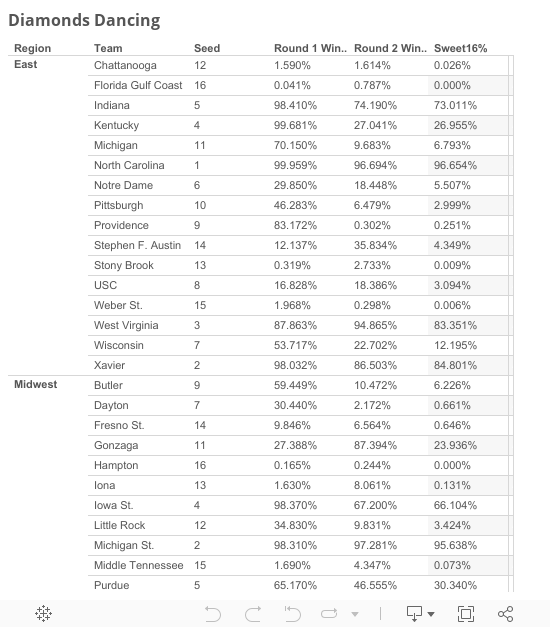
As we look at the results of the model, a few patterns emerge:
• The model is incredibly confident in a lot of 8/9 and 7/10 picks. At times, the model is too confident. As these match-ups are the hardest to predict, this is where the model is the least accurate, though not by much. Testing the model on tournament data from 2002 and 2003, the model still managed to pick about 75% of the match-ups correctly. In terns of total accuracy, the model correctly predicted 83% of all match-ups .
• In terms of Giant Killers, or teams that may be in line to pull a big upset in Round 1, the model likes the First Four participants, 11-seeds Wichita State and Michigan/Tulsa. Interestingly enough, a team from the First Four has made the Round of 32 each year since the First Four’s inception in 2011. Also look out for Little Rock, Northern Iowa, and Gonzaga as double-digit seeds.
• Stephen F. Austin is an interesting case this year. In Round 1, they have a 12.1% chance of beating West Virginia in the East Region. However, if they somehow manage to pull the upset, their chances of winning in Round 2, sit at 35.84%, against either Notre Dame (more on them in a bit) or Michigan/Tulsa . According to the model, S.F. Austin’s Round 2 winning percentage would be the highest for a 13-seed or worse facing at least an 11 or better seed since KenPom started keeping advanced stats.
• If we’re talking Cinderellas, the model particularly likes Iowa, giving them a 73% chance of making the Second Weekend, likely taking down Villanova on the way. Along with Iowa comes Wichita State and VCU as the most likely double-digit seeds to make the second weekend.
• According to historic model estimates, UNC Asheville sits as the 6th mostly likely 15-seed to win a first round match-up since 2002. 2 of those 5 15-seeds (2013 Florida Gulf Coast and 2012 Lehigh) with at least a 5% chance to win in Round 1 won their match-ups. If you NEED to pick a 15-seed, you might consider UNC Asheville.
• The model doesn’t seem to like Notre Dame in either the first or the second round. In fact, Notre Dame is the only Top 6 seed that has a winning percentage lower than 30% in both Round 1 and Round 2. This could be because Notre Dame doesn’t really excel in many categories that the model values. They are an average team on defense, allowing 1.037 Points Per Possession, equal to the NCAA D1 average . They don’t turn the ball over, though they don’t force turnovers either, giving the ball away on 14.8% of their possessions and forcing the same percentage on defense. Finally, they don’t guard the 3-point line particularly well, allowing opponents to shoot 37.6% from behind the arc on nearly 20 attempts per game.
Disclaimers
A point to remember when looking at this model: It is a logistic regression, meaning that it measures a team’s chances of winning a game in percentages. That seems fitting for March Madness, considering that anything can happen. Even teams with less than a 1% chance of winning have won in the past. Models like these can give you a solid prediction of what may happen, but nothing is certain. That’s why the boys lace ‘em up and why we watch them. Good luck picking your brackets, enjoy the Madness, and continue to pray for the return of Gus Johnson to the NCAA Tournament sidelines in the near future.
Hey Max,
I also produce win probabilities for each team in each round. Can I have your data to compare? I don’t seem to be able to download it from your graphic. Can you share a link to a public Google Sheet or post the .csv file for anyone who wants the data?
Thanks,
Jim
Davidson ’09